Edge computing vs cloud are redefining how modern systems process data, deciding where computation happens and how quickly results arrive. This guide contrasts edge vs cloud architecture, latency, data gravity, and governance considerations that drive performance and cost. When to use edge computing is addressed through a practical lens, showing where a hybrid cloud edge solution shines. We highlight edge computing use cases and cloud computing benefits and drawbacks to give a balanced, real-world view. The takeaway is a practical path that balances latency, privacy, and total cost of ownership across devices and centralized services.
From another angle, many organizations describe this approach as on-device processing and local data handling that happens before information ever leaves the premises. Concepts like fog computing, near-edge intelligence, and gateway-driven processing emphasize distributing work to the closest points to data sources, rather than relying solely on the cloud. By framing the decision in terms of local compute, gateway analytics, and centralized coordination, teams can map workloads to latency, governance, and resilience requirements in a way that mirrors the original discussion. This LSIs-aligned framing supports comparing time-sensitive tasks, offline operation, and scalable analytics without repeating the exact keyword phrases.
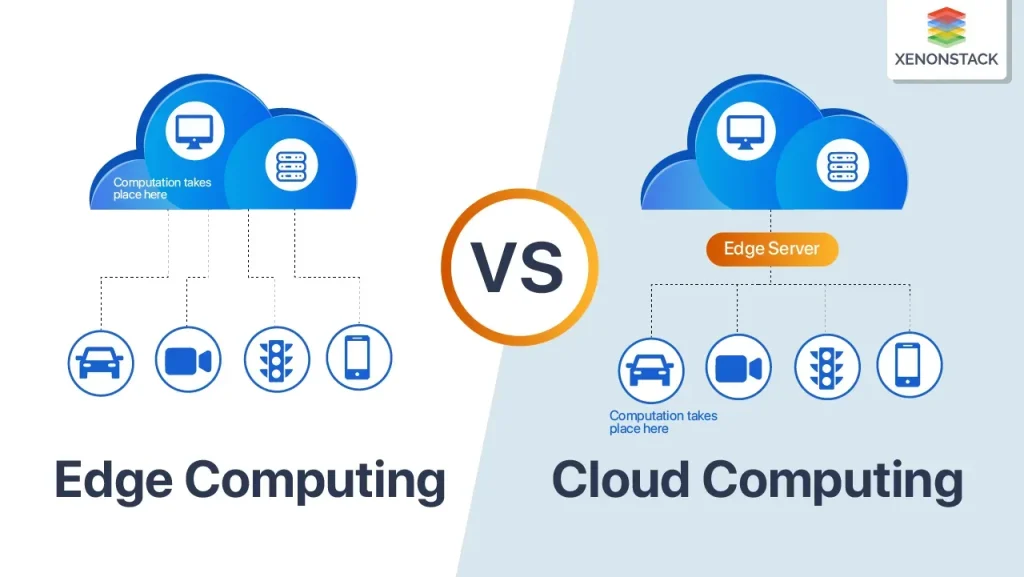
Edge computing vs cloud: Navigating decisions in a hybrid cloud edge solution
Edge computing vs cloud describes where data is processed and how quickly decisions are made, highlighting near-data processing, local inference, and reduced data movement. This distinction matters for latency-sensitive workloads and architectures that demand offline operation, privacy, and governance. Within the context of edge vs cloud architecture, real-world edge computing use cases—such as on-site analytics in manufacturing, autonomous devices in transportation, and local monitoring in energy systems—illustrate how processing at the edge can deliver deterministic latency and resilience.
A practical path is to map workloads to latency requirements, connectivity, data governance, and compute intensity. When to use edge computing becomes clearer when you separate what must respond in milliseconds from what benefits from centralized training and global orchestration in the cloud. Weigh cloud computing benefits and drawbacks alongside the benefits of edge processing to design a hybrid cloud edge solution that minimizes data movement while maximizing local responsiveness and governance.
Edge computing use cases and architectural patterns for scalable hybrid deployments
Edge computing use cases span manufacturing, retail, healthcare, and utilities, where edge devices perform conditioning, local inference, and data filtering to reduce bandwidth and latency. In manufacturing, sensors on the shop floor enable rapid control loops, anomaly detection, and fault monitoring without waiting for cloud round-trips. In healthcare, patient monitors can trigger alerts locally while de-identifying data for cloud analytics, preserving privacy and enabling longer-term insights.
Architectural patterns for a scalable hybrid deployment organize capabilities into edge tier, gateway/near-edge tier, and cloud tier. The edge tier brings preprocessing and local inference closer to data sources, reducing data movement and enabling offline operation. The gateway tier aggregates results, enforces policy, and bridges edge devices with centralized services, while the cloud tier provides analytics, model training, and governance at scale. This hybrid cloud edge solution supports end-to-end orchestration, security, and observability across distributed sites.
Frequently Asked Questions
Edge computing vs cloud: when to use edge computing in edge vs cloud architecture and what are common edge computing use cases?
Edge computing vs cloud decisions hinge on latency, connectivity, data governance, and compute needs. Use edge computing when decisions must happen in milliseconds, networks are unreliable, or data must stay local—common edge computing use cases include factory-floor analytics, autonomous devices, and local inference at gateways. For broader analytics, model training, and global coordination, cloud computing offers scalable resources but introduces latency and data transfer costs. Many organizations implement a hybrid cloud edge solution, running time-sensitive workloads at the edge while leveraging cloud resources for training, governance, and long-term storage.
Edge computing vs cloud: how does a hybrid cloud edge solution balance benefits and drawbacks and support edge computing use cases?
A hybrid cloud edge solution balances the cloud computing benefits and drawbacks with the needs of edge computing use cases. Start by mapping workloads to latency targets, data governance, and operational maturity. Place latency-sensitive processing, preprocessing, and local inference at the edge, while reserving training, batch analytics, and centralized governance for the cloud. Build secure data pipelines, enable over-the-air updates, and implement end-to-end observability. Leveraging cloud computing benefits like elasticity and global coordination, this approach also mitigates drawbacks such as data transfer costs and network dependency by reducing data movement and keeping sensitive data local.
| Aspect | Key Points |
|---|---|
| Core Difference | Edge computing places processing closer to where data is generated (devices, gateways, local data centers) to reduce latency and data movement, while cloud computing centralizes processing in remote data centers for scale and global coordination. Key distinctions include latency sensitivity, data gravity, connectivity requirements, and governance considerations. |
| Latency, Data Volume, Autonomy | Edge architectures favor near real-time decisions, local resilience, and operation with limited bandwidth; Cloud architectures excel at large-scale analytics, ML training, and cross-site coordination. Latency, throughput, reliability, and data transport costs shape the best approach. |
| Decision Framework Axes |
|
| Edge Computing Use Cases |
|
| Architectural Patterns |
|
| Cost, Performance & Security |
|
| Data Management & Integration |
|
| Cloud Computing Benefits & Drawbacks |
|
| Hybrid Cloud Edge Solution |
|
| Implementation Considerations & Roadmap |
|
| Measuring Success & Pitfalls |
|
Summary
Edge computing vs cloud describes a spectrum rather than a binary choice, emphasizing hybrid approaches that balance local processing with centralized analytics. In practice, most modern architectures blend edge and cloud capabilities to minimize latency, manage data gravity, and optimize costs while preserving governance and security. A practical strategy is to map workloads to the right tier, adopt a tiered architecture (edge, gateway, cloud), and implement robust orchestration and observability. By combining near-term responsiveness at the edge with the scale and intelligence of the cloud, organizations can achieve resilient systems that adapt to evolving workloads and regulatory requirements. The result is a cohesive technology strategy that prioritizes latency-sensitive tasks at the edge and leverages cloud resources for training, analytics, and governance.

