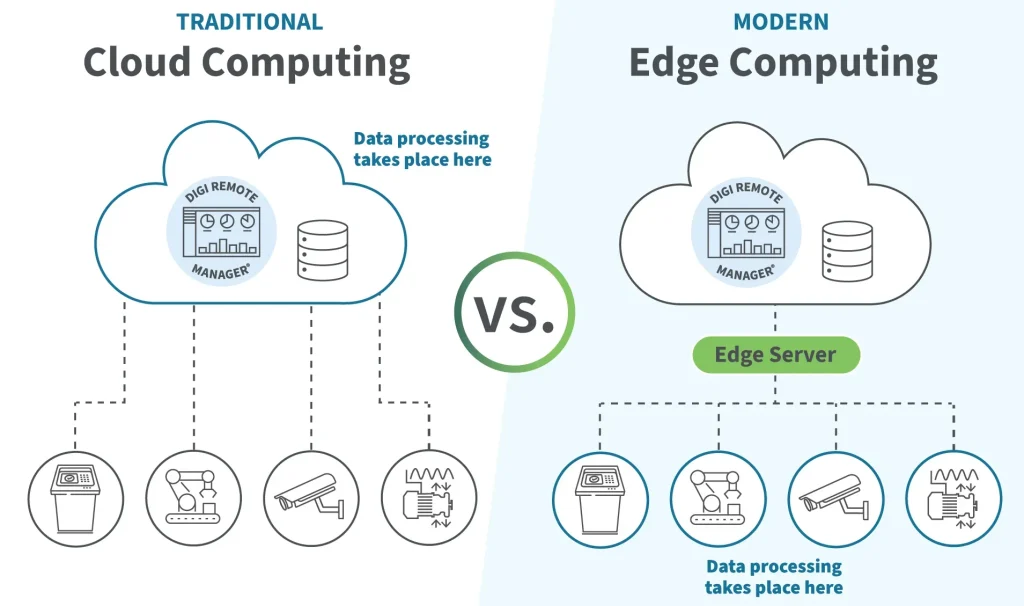
Edge Computing vs Cloud Technology frames a pivotal choice in modern architectures, where immediacy, privacy, and scale compete for attention. Edge computing brings processing closer to the data source, enabling real-time data processing and faster, localized decisions. In contrast, cloud technology offers centralized scalability, mature services, and broad reach that support large analytics and rapid experimentation. A practical strategy blends both approaches—hybrid cloud deployments and edge vs cloud orchestration—to balance latency with scalability. Understanding where to process data—whether at the edge or in the cloud—helps organizations optimize performance, cost, and governance.
Viewed through a distributed computing lens, near-edge processing emphasizes local analytics, on-device intelligence, and minimized data movement. Alternatively described as fog computing or peripheral processing, this approach keeps critical decisions close to where data is created. The cloud remains the scalable backbone for heavy analytics, machine learning, and centralized governance, forming an edge-to-cloud continuum. Framing the topic with terms like local data processing, proximity-based computing, and hybrid cloud helps readers grasp the shared ideas without getting hung up on labels.
Edge Computing vs Cloud Technology: Navigating Real-Time Data Processing in a Hybrid Cloud Strategy
Edge Computing vs Cloud Technology is not a binary choice but a spectrum that centers on where real-time data processing happens. By processing data closer to the source, edge computing dramatically reduces end-to-end latency, enabling immediate actions such as anomaly detection, automated control, and on-site decision-making. When paired with a hybrid cloud approach, organizations can keep latency-sensitive workloads at the edge while leveraging cloud technology for scalable analytics, historical insights, and governance. This balance helps conserve bandwidth, improve resilience, and support offline or intermittent connectivity scenarios that are common in manufacturing floors, remote facilities, and autonomous systems.
In practice, a hybrid cloud strategy aligns edge computing with cloud technology to optimize for both speed and scale. The decision framework often hinges on latency tolerance, data gravity, and security requirements. Edge workloads handle real-time data processing and privacy-preserving tasks locally, while the cloud handles heavy analytics, long-term storage, and centralized orchestration. Using this edge vs cloud pattern, organizations can design data flows that minimize unnecessary transmission, reduce bandwidth costs, and maintain governance across distributed environments.
Edge vs Cloud: Crafting a Hybrid Cloud Architecture for Scalable Analytics and Secure Data Governance
A practical hybrid architecture starts with a clear delineation of what data stays at the edge, what is summarized locally, and what is sent to the cloud for deeper analysis. This edge-first approach delivers low latency and local autonomy, enabling real-time data processing at the source, while the cloud provides scalable compute, large-scale machine learning, and centralized data governance. The result is a resilient, scalable system where edge gateways, micro data centers, and fog elements collaborate with cloud platforms to support both fast responses and long-term insights.
To realize this, organizations should design uniform security policies, interoperable interfaces, and comprehensive observability across edge and cloud boundaries. A successful hybrid cloud setup requires careful data governance, data retention policies, and a clear data flow diagram that specifies which data moves to the cloud and which remains locally. Start with a phased approach—deploy edge-enabled processing for time-sensitive tasks, then extend analytics and storage to the cloud—before scaling to a full edge-to-cloud ecosystem that sustains real-time data processing, governance, and scalable analytics.
Frequently Asked Questions
What are the main trade-offs when choosing Edge Computing vs Cloud Technology for real-time data processing?
Key trade-offs include latency and immediacy (edge provides lower end-to-end latency for real-time data processing), bandwidth usage (edge reduces data sent upstream by filtering or summarizing), connectivity resilience (edge can operate with intermittent connectivity), data locality and compliance (edge keeps data on-site when required), and cost and complexity (edge capex vs cloud operating expenses and ongoing management). In practice, many organizations adopt a hybrid approach: place latency-sensitive tasks at the edge and use the cloud for heavy analytics and long-term storage. The best fit depends on data gravity, regulatory requirements, and total cost of ownership.
How does a hybrid cloud approach optimize Edge Computing vs Cloud Technology for performance, cost, and governance?
A hybrid cloud approach aligns with Edge Computing vs Cloud Technology by keeping latency-sensitive processing at the edge while routing analytics and storage to the cloud. This reduces end-to-end latency, lowers data transfer costs, and enables scalable analytics and governance through centralized controls. Key steps include defining data flow (what stays at the edge vs what is sent to the cloud), ensuring interoperable, standards-based interfaces, and applying unified security policies across boundaries. The result is a balanced architecture that combines real-time data processing at the edge with cloud technology for deeper insights and compliance.
| Aspect | Edge Computing | Cloud Technology | Key Takeaways |
|---|---|---|---|
| Latency / Real-time processing | Low latency; local processing near data sources | Higher latency due to round-trip to centralized data center | Use edge for time-sensitive tasks; cloud for heavy analytics when latency is less critical |
| Data Movement / Bandwidth | Filters/summarizes locally; reduces upstream data | Centralized storage; scalable compute; data moves upstream | Edge reduces bandwidth; cloud handles data at scale |
| Connectivity | Operates with intermittent connectivity; offline operation | Requires reliable connectivity for services | Hybrid designs mitigate risk; maintain essential operations at edge |
| Data Locality / Compliance | On-site data stays local; supports privacy | Centralized governance; broad reach; data may move across borders | Hybrid supports compliance and governance across jurisdictions |
| Cost Model | Capex for devices; ongoing maintenance | Opex per usage; scalable pricing | Hybrid balances capex vs opex |
| Ideal Use Cases | Real-time monitoring, remote/limited connectivity, privacy focus, autonomous systems | Batch analytics, AI training, SaaS, global deployments | Edge for latency-critical tasks; cloud for scale and analytics |
| Management & Security | Edge security, firmware management, local controls | Centralized security, governance, monitoring | Ensure consistent security across edge and cloud boundaries |
Summary
In summary, Edge Computing vs Cloud Technology represents a continuum rather than a binary choice. Edge computing delivers immediacy, resilience, and privacy for time-sensitive workloads, while cloud technology provides scale, broad service ecosystems, and global reach. A pragmatic hybrid or two-tier approach—placing critical processing at the edge and leveraging the cloud for analytics, storage, and governance—often yields the best balance of performance, cost, and governance. By applying a clear decision framework that accounts for latency, data gravity, connectivity, and compliance, organizations can design architectures that unlock real-time insights while maintaining scalability and control. The future of computing lies in orchestrating both edge and cloud technologies to maximize value across industries.

